电源
91篇文章
前面的文章我们一起了解了USB的包结构以及令牌包,今天我们来说说USB的数据包和握手包.
顾名思义,数据包就是用来传输数据的,在USB1.1协议中,只有两种数据包:DATA0包和DATA1包。在USB2.中又增加了DATA2和 MDATA包,主要用在高速分裂事务和高速高带宽同步传输中。
数据包都具有同样的结构:一个同步域,后面跟整数字节的数据,然后是CRC16校验,最后是包结束符EOP,如图1所示。
图1
之所以有不同类型的数据包,是用在当握手包出错时纠错.下面以DATA0包和DATA1包的切换为例进行具体的解释。
主机和设备都会维护自己的一个数据包类型切换机制:当数据包成功发送或者接收时,数据包类型切换。当检测到对方所使用的数据包类型不对时,USB系统认为这发生了一个错误,并试图从错误中恢复。数据包类型不匹配主要发生在握手包被损坏的情形。当一端已经正确接收到数据并返回确认信号时,确认信号却在传输过程中被损坏。这时另一端就无法知道刚刚发送的数据是否已经成功,这时它只好保持自己的数据包的类型不变。如果对方下一次使用的数据包类型跟自己的不一致,则说明它刚刚已经成功接收到数据包了(因为它已经做了数据包切换,只有正确接收才会如此);如果对方下一次使用的数据包类型跟自己的一致,则说明对方没有切换数据包类型,也就是说,刚刚的数据包没有发送成功,这是上一次的重试操作。
握手包有ACK、NAK、 STALL和NYET。ACK表示正确接收数据,并且有足够的空间来容纳数据。主机和设备都可以用ACK来确认,而NAK、 STALL、NYET只有设备能够返回,主机不能使用这些握手包。
图2
>NAK表示没有数据需要返回,或者数据正确接收但是没有足够的空间来容纳它们。当主机收到NAK时,知道设备还未准备好,主机会在以后合适的时机进行重试传输。
> STALL表示设备无法执行这个请求,或者端点已经被挂起了,它表示一种错误的状态。设备返回 STLSTALL后,需要主机进行干预才能解除这种状态。
>NYET只在USB2.0的高速设备输出事务中使用,它表示设备本次数据成功接收,但是没有足够的空间来接收下一次数据。主机在下一次输出数据时,将先使用PING令牌包来试探设备是否有空间接收数据,以避免不必要的带宽浪费。
需要注意的是,返回NAK并不表示数据出错,只是说明设备暂时没有数据传输或者暂时没有能力接收数据。当USB主机或者设备检测到数据出错时(如CRC校验错、PID校验错、位填充错等),将什么都不返回。这时等待接收握手包的一方就会收不到握手包从而等待超时。
以上就是数据包和握手包的内容,你明白了吗?
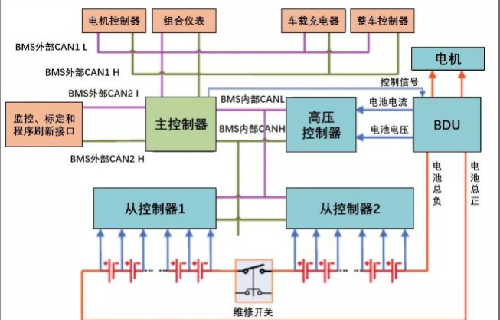
大家好!我是张飞实战电子蔡琰老师,今天给大家分享BMS电池管理系统。
随着新能源、可穿戴设备等的发展,BMS成为热议的话题,经久不衰,这篇文章我们就一起来学习一些关于BMS的知识。
BMS是对电池进行监控和管理的系统(Battery Management System),通过对电池的电压、电流、温度、剩余容量(SOC)、放电功率,报告电池劣化程度(SOH)、电池均衡管理、报警提醒等参数采集、计算进而控制电池放电过程,实现对电池的保护,提升电池综合性能的管理系统。它还根据电池的电压电流及温度用算法控制最大输出功率以获得最大续航,用算法控制充电机进行最佳电流的充电,它通过通信线与其他控制单元进行通信,比如我们手机或新能源汽车的快充、电量显示等都与BMS有着密切的关系。
提到电池,一般被分为动力电池和非动力电池,新能源汽车的动力来源一般主要是以动力电池为主。一般,动力电池实际上就是为交通运输工具提供动力来源的一种电源。它与普通电池的主要区别为动力电池相比于普通电池,其放电功率大。它可以在很短的时间内将电池的电放完。动力电池一般容量要小于非动力电池。
一般电池后面的xxC它表示了电池的放电能力,C:用来表示电池充放电电流大小的比率,即倍率。充放电倍率=充放电电流/额定容量,例如1000mAh的电池,1C放电,就是1A放电,那么1个小时就可以放完,2C放电,就是2A放电,半个小时就可以放完。当然不同材质的电池,放电能力也是不一样的。
生产制造和使用过程的差异性,造成了动力电池单体天然就存在着不一致性。不一致性主要表现在单体容量、内阻、自放电率、充放电效率等方面。单体的不一致,传导至动力电池包,必然的带来了动力电池包容量的损失,进而造成寿命的下降。
根据木桶短板效应,充电和放电时都是性能最差的单体先达到截止条件,其他还有一部分能力并未释放出来,这样就造成了浪费。
电池单体的不一致,会随着时间的推移,在温度以及振动条件等随机因素的影响下进一步恶化,趋势无法逆转,但可以干预,降低它的恶化速率。方法之一就是通过电池管理系统对电芯实施均衡。
均衡包括主动均衡和被动均衡,被动均衡,运用电阻器,将高电压或者高荷电量电芯的能量消耗掉,以达到减小不同电芯之间差距的目的,是一种能量的消耗。主动均衡,运用储能器件等,将荷载较多能量的电芯部分能量转移到能量较少的电芯上去,是能量的转移。
但是均衡也存在一定的局限性,被动均衡,电流无法完全按照实际需求去做,因为通过电阻消耗的能量,转化成热量,对电池管理系统以及电池包都会产生不良影响;主动均衡,需要配置相应电路和储能器件,体积大,成本上升,这两个条件一起决定了主动均衡不容易推广应用。电池包的每个充电放电过程,都伴随着一部分电池局部的附加充放过程,无形中增加了电池的循环次数。
在一些系统中对成本的要求比较高,比如手扶电动两轮车,在这个系统中BMS电池管理系统设计也相对简单一些,仅由一颗专用的管理芯片即可实现电池管理,当然这个管理是纯硬件的,没有加入软件,实现一些基本的功能:正常充放电、过充过放、温度保护、平衡等。
在复杂的管理系统中,从系统层次来进行架构管理,会引入一些控制单元(如单片机)做一些控制算法,它不仅包含硬件,还包含底层软件、应用层软件等。
如上图(来源于网络),分为主控,从控,电压电流采集控制、仪表显示等功能,非常复杂。单单这一个系统里面用到的单片机数量是十分可观的。
上面我们简单对BMS一些问题进行了了解,作为控制工程师,首先学好单片机是非常重要的,还等什么,赶紧行动起来吧!

说到文字池,首先第一个问题:什么是文字池?文字池又叫literal pool,它的本质就是ARM汇编语言代码节中的一块用来存放常量数据而非可执行代码的内存块。
那为什么要使用文字池呢?当想要在一条指令中使用一个 4字节长度的常量数据(这个数据可能是内存地址,可能是数字常量)的时候,由于ARM指令集是定长的(ARM指令4字节或Thumb指令2字节),就无法把这个4字节的常量数据编码在一条编译后的指令中。此时,ARM编译器(编译C源程序)/汇编器(编译汇编程序) 就会在代码节中分配一块内存,并把这个4字节的数据常量保存起来,之后,再使用一条指令把这个4 字节的数字常量加载到寄存器中参与运算。 在写C程序中,文字池的分配是由编译器在编译时自行分配安排的,但是,在写汇编程序时,开发者可以自己进行文字池的分配,当然如果没有自己分配汇编器也会代劳。不管何种情况,这不影响我们来了解学习一下文字池的知识。
LDR Rd,=const 伪指令可在单个指令中构造任何 32 位数字常数。 使用此伪指令可生成超出MOV和MVN指令范围的常数。LDR 伪指令可为特定的常数生成最高效的单个指令:如果可以用单个MOV或MVN 指令构造该常数,则汇编器会生成适当的指令。如果不能用单个MOV或MVN 指令构造该常数,则汇编器会执行下列操作:将该值放入文字池中,生成一个使用程序相对地址的 LDR 指令,用于从文字池中读取该常数。说的通俗一点,如果LDR Rd, =const能够被转换成MOV 或者MVN指令,则汇编器将转换成它成为相应的指令,如果不能被转换,则汇编器会将value存放在文字池中,并且产生一个LDR指令操作。
汇编器默认把文字池放在每一个代码节的末尾处。代码节的末尾的确定或者是由汇编源文件尾部的指示符END确定,或者由相邻代码节的起始行AREA确定。在大的代码节中(通俗理解为这个节中的代码量比较大),默认文字池在最后,可能与代码节中一条或多条LDR伪指令的距离很远,可能超出LDR伪指令操作数的寻址范围。
当伪指令是32位时,在ARM或Thumb代码中,必须小于4K字节,文字池常量数据的位置可以是在伪指令的前面,也可以是在伪指令的后面。当伪指令是16位Thumb指令时,必须小于1K字节,且文字池必须位于伪指令的后面。
LDR Rd, =const 伪指令需要一个文字池来存放立即数常量时,汇编器会检查已经存在的文字池中是否有相同的常量并且检查文字池是否在伪指令允许寻址的范围内。如果条件满足,汇编器引用这个满足条件的常量,否则汇编器会尝试把该常量值放到文字池未用的空间中。如果空间地址超出伪指令的寻址范围,汇编器会产生一条错误信息。这种情况下,程序员必须得自己用指示符LTORG在代码中设置增加一个文字池。指示符LTORG放在导致错误的伪指令后面,并且位于伪指令LDR的有效寻址范围内(一般节的代码量不是特别大的情况下,可以放于中间位置)。而且要保证设置的这个文字池,处理器执行代码的时候不会执行到这个地址。 它们应放在无条件跳转指令的后面,或者放在子例程末尾处的返回指令的后面。
应用举例如下:
Fun1
LDR R0, =0X12345678
ADD R1, R1, R0
BX LR ;子程序返回
LTORG ;声明文字池,存储0x12345678
POOL SPACE 20
好了,关于文字池,本片文章就讲到这里了,大家有不明白的地方可以留言提问哦,谢谢大家。

在程序的开发过程中,调试语句是程序开发的一种主要的辅助手段。C语言主要的调试语句使用的是printf,它的定位是系统的标准输出。在嵌入式系统中,printf()的输出可能是屏幕、也可能是串口。
#字符串转化操作符
在编译系统中,可以使用#将当前的内容转换成字符串,例如:
#define dprint(expr) printf(“<main>%s = %d n”,#expr,expr)
①在程序中可以使用如下的方式调用:
在以上的例子中,使用#expr表示根据宏中的参数(即表达式的内容),生成一个字符串。因此,#expr代表将dprint(expr)括号中的内容生成一个字符串。一般来说,宏中的参数将作为一个变量被引用,而增加了#修饰之后的表达式,即代表了将宏中的参数名称直接转换成字符串。
上述过程同样是由编译器产生的,编译器在编译源文件的时候,如果遇到了类似的宏(示例中的dprint)会自动根据程序中表达式的内容,生成一个字符串的宏(示例中的#expr)。这样宏同样可以在程序中表示一个字符串。
②进一步,在程序中可以按照如下的形式调用以上宏:
从运行结果的第一行可以看到,编译器的生成字符串的时候,不会照搬宏参数中的所有内容,注释类的内容是不会被放入字符串的宏,这也是因为去注释是编译器预处理阶段的内容,也就是说在实际的编译过程之前,程序中的注释已经被去掉。从运行结果的第二行看出,由于a不是整数,而是字符串的指针,因此打印出a的值实际是变量a的地址,而字符串的内容依然是a。从运行结果的第三行看出,对于直接写入程序的数值(立即数),编译器也可以将它的内容转换成字符串。
这种方式的优点是可以用统一的方法打印表达式的内容,在程序的调试过程中可以方便直观地看到转换成字符串之后的表达式。具体的表达式的内容是什么,是由编译器“自动”写入程序中的,这样使用相同的宏打印所有表达式的字符串。
由于#expr本质就是一个表示字符串的宏,因此在程序中也可以不使用%打印它的内容,而是可以将其直接和其他的字符串连接。上面的宏可以等价为以下的形式:
#define dprint (expr) printf(“<main>” #expr “=%d n”,expr)
注意:#是C语言预处理阶段的字符串转化操作符,可以将宏中的内容转换成字符串。
##:连接操作符
在编译系统中,##是C语言中的连接操作符,可以在编译的预处理阶段实现字符串连接的操作。
以下的程序是一个使用##的示例:
#define test(x) test ## x
void test1(int a) void test2(char *s)
{ {
printf(“Test 1 interger: %d n”,a); printf(“Test 2 String : %s n”,s);
} }
在上面这个程序,test(x)宏被定义为test##x,它表示test字符串和x字符串的连接,因此test(1)将被预处理器为:test1,而test(2)将被预处理器处理为:test2。预处理器仅仅是转换字符串而已,所以上面的test1和test2刚好转换成两个函数的名称。
条件编译调试语句
在嵌入式系统的调试中,调试语句可以在程序运行的过程中输出程序的运行状态。然而调试语句的调用是有开销的,在最终发布版的程序中,调试语句都是应该去掉的。去掉调试语句最简单的方式将其注释掉,但是主要就需要维护两种源程序:一种是带有调试语句的调试版程序,另一种是不带有调试语句的发布版程序。这显然不是一种很好的方式,理想的方式是只有一套源程序,根据不同的条件编译选项,编译出不同的调试版和发布版的程序。
在实现的过程中,可以使用一个调试宏来控制调试语句的开关,如下所示:
#ifndef USE_DEBUG
#define DEBUG_OUT(fmt,args...) printf(“File:%s Function:%s Line:%d”fmt,_FILE_,_FUNCTION_,_LINE_,
##args)
#else
#define DEBUG_OUT(fmt,args...)
#endif
在上面的程序中,宏USE_DEBUG用来控制调试语句的开关,当USE_DEBUG被定义的时候,将调试语句DEBUG_OUT定义成上面部分的形式,当没有定义的时候,宏定义为空,在这种情况下,即使程序中写很多DEBUG_OUT,编译器也会将其处理为没有任何语句。
注意:一条语句太长换行需要在每行的结尾使用,表示下一行的内容是和上面的连续的。
使用do...while的宏定义
使用宏定义可以将一些较为短小的功能封装,方便使用。宏的形式和函数类似,但是可以节省函数跳转的开销。如何将一个语句封装成一个宏,在程序中常常使用do...while(0)的形式,例如,对一个简单打印的语句的宏封装如下所示:
#define HELLO(str) do{ printf(“hello:%sn”,str); }while(0)
在上面这个语句中,将实际执行的功能封装在一个do...while(0)循环内。事实上,do...while(0)由于条件不成立,因此循环体之间的语句只会执行一次。然而,这样做的好处是就是可以让do...while(0)之中的语句像函数一样使用,而不必担心编译器发生错误。
如果直接把后面语句放入宏使用,不用do...while,那么宏在一般顺序执行语句中使用没有问题,如果使用在if...else中,都会发生错误编译。事实上,一般的语句中多一个分号,只相当于多了一条空语句,没有影响。这里却是在if语句后面多出一个分号,它们代表if语句的结束。因此,后面的else就会被视为一条新的语句(相当于前面没有if只有else),这就会发生编译错误。
而如果使用do...while(0)的形式就没有以上的问题,而且一般的C语言编译器都会对do...while(0)进行优化,使其和一般的一条函数等价,在其中可以含有任意条语句。

前情提要:前面一篇说了我设计这个全隔离小模块的想法和原理图设计,那么接下来就说下我的PCB设计过程,有些需要注意的点,我经历的坎坷分享给大家,希望能有些值得借鉴的地方。
对于PCB设计,虽然我设计的是个小模块,然而不能因为产品小就大意,每个产品都有它的特点,都有需要注意的地方,经验积累都是一点一滴开始的。
首先是左进右出原则,左边是USB端口,右边是TTL端口。(当然这个根据个人喜好,我的原则就是接口在板边)
导入后布局前首先就是设置规则,有了规则约束布局走线自然也顺畅些了,没规矩不成方圆。
继续简单看下我的常规规则设置,
1、间距的设置,常规间距我是配置0.2,敷铜间距0.5;根据实际需求设定。
2、线宽的范围放大,推荐的一般我不会改变。
3、孔径的大小我一般会把范围设置大点,个人调节不受约束。
4、一些间距的设置一般我都会设置为0,布局以及走线靠个人把控,比如孔到孔的间距,最小阻焊的间距,丝印到阻焊的间距,丝印到丝印的间距等。这个都可以根据自己需要设置。
规则设置好就开始布局了,布局过程遵循规则就可以了。
因为全隔离,有隔离芯片加隔离电源,隔离的要分开,考虑敷铜的方便,所以在布局的时候把模块要摆放好。
布局模块化先把位置放置好,USB端口已经说过了,接着看下转化芯片的放置,直接上图看下吧。
接下来看下隔离部分的布局,前面说了因为全隔离,通过敷铜共地,然后就要考虑隔离部分器件的摆放。
布局的过程也就对走线也考虑了,那么在走线的时候就可以顺利很多了。当然会有小的调整。
大体就是这样的。
走线主要注意的是线宽,常规都是推荐线宽就可以了,电源和地的部分还是需要宽一些,一般我用0.4mm。再有需要注意的一点是最后需要加泪滴效果,为了避免焊接线容易断。
还有敷铜后需要加一些过孔,为了铜皮的电位平等。这些都是需要注意的点。丝印的调整,以及一些版本号,日期号的添加,这些都是很有必要的。
这里分享下我的最终实现效果:
到这里,这个全隔离小模块就实现了,其实并不难,后面就是打板事宜了,感兴趣的可以试着实现一下,真正的实践才是真的成长,后面我还会陆续分享我的视频实现过程,那是整个过程走了一遍,希望能给到大家一些值得借鉴的东西,还希望大家能多跟我交流和沟通。我陆续分享乌云踏雪系列的转换模块的实现过程,有视频,有文章,这个是乌云踏雪系列的C1A(Connect),后面会实现更多。有兴趣的就持续关注下哈,如果有想实现的点子也可以跟我们交流,一起实现哈。
 蔡琰
蔡琰