电源
91篇文章

大家好!我是张飞实战电子黄忠老师!今天给大家聊一聊单片机堆栈.
单片机堆栈是什么?
简单来说是在RAM区的一块存储空间,在系统空间中用作临时数据存储,遵循后进先出的原则。
栈空间操作的关键点之一就是栈指针寄存器,每次执行栈操作时,栈指针的内容自动调整。
按照通常的说法,向栈中存储数据称为“压栈”(使用PUSH指令),恢复数据称为“出栈”(使用POP指令)。根据所使用架构的不同,有些处理器在向栈存入数据时地址会自动增加,而有些则会减小。
这就意味着栈指针始终指向栈空间的最后一个数据,在执行数据存储前(PUSH),栈指针会首先减小。
PUSH和POP通常用在函数或子程序的开始和结尾处。在函数开始执行时,PUSH操作将寄存器的当前内容存入栈空间;执行结束前,POP又将栈空间存储的数据恢复。一般说来,对每个寄存器的PUSH操作都应相应的进行POP操作。否则恢复的数据可能无法对应之前的寄存器,这样会导致无法预期的后果,比如栈溢出。
下面看一下压栈和出栈的操作过程:
再来说一下堆栈的作用:
子程序调用和中断服务时,CPU自动将当前PC值压栈保存,返回时自动将PC值弹栈。
保护现场/恢复现场。
数据传输
再来说一下堆栈操作的一些规则。
比如Cortex-M0处理器每次出栈以及压栈操作的最小单位是4字节(32位),还可以使用一条指令实现对多个寄存器的压栈和出栈操作。显然Cortex-M0的栈空间被设计为字对齐的(地址值必须是4的倍数,比如0x0、0x4、0x8等)。
对于Cortex-M0处理器,可以通过R13或SP访问R13或SP,根据处理器状态和CONTROL寄存器值的不同,访问的栈指针可以是主栈指针(MSP),也可以是进程栈指针(PSP)。许多简单的应用只会用到一个栈指针,一般默认是主栈指针(MSP),进程栈指针通过只用于嵌入式应用的操作系统(OS)。
对于Cortex-M0处理器由于栈是向下生长的(满递减),内存的上边界通常会被用作栈指针的初始值。例如,如果内存区域为0x20000000~0x20007FFF,我们可以将栈指针的初始值设为0x20008000,在这种情况下,第一次压栈操作会将数据存至0x20007FFC开始的字中,这也是内存的最高4字节。

今天我们来详细地说说数据包的结构以及它们的传输过程。
USB是串行总线,所以数据是一位一位地在数据线上传送的。既然是一位一位地传送,就存在着一个数据位先后的问题。usb使用的是LSB在前的方式,即先出来的是最低位数据,接下来是次低位,最后是最高位(MSB)。一个包,又被分成了很多个域(field),而LSB、MSB就是以域为单位来划分的。
前面说过,USB数据在发送到总线上之前,要先经过位填充,再经过NRZ1编码。在这里讨论时,所用的数据都是原始的数据,即没有经过位填充和NRZ编码的原始数据。以后也是如此,凡是没有明确说明是位填充或NRZI编码过的数据,默认为原始的数据。另外还有一个数据传输方向的问题,因为在USB系统中,主机处于主导地位,所以把从设备到主机的数据叫做输入,从主机到设备的数据叫做输出。
USB总线上传输数据是以包为基本单位的。一个包被分成不同的域。根据不同类型的包,所包含的域是不一样的。但是不同的包有个共同的特点,就是都要以同步域开始,紧跟一个包标识符PD( Packet Identifier),最终以包结束符EOP(End Of Packet)来结束这个包。
同步域是用来告诉USB的串行接口引擎数据要开始传输了,请做好准备。除此之外,同步域还可以用来同步主机端和设备端的数据时钟,因为同步域是以一串0开始的,而0在USB总线上就被编码为电平翻转,结果就是每个数据位都发生电平变化,这让串行接口引擎很容易就能恢复出采样时钟信号;对于全速设备和低速设备,同步域使用的是0000001(二进制数,线上的发送顺序);对于高速设备,同步域使用的是31个0,后面跟1个1(需要注意的是,这是对发送端的要求,接收端解码时,0的个数可以少于这个数)。
图1是一个全速或者低速USB数据包的同步域经过NRZ编码后的波形。这个波形有7次电平翻转,即对应着7个0,最后一个电平不翻转,即对应着1个1当串行接口引擎检测到一个位的数据未发生翻转后(即收到数据1),就认为包标识符PID开始了,如图1.9.1中的PID0PD1,就是包标识符的最低两位。
图1 全速设备和低速设备的同步域
包结束符EOP,对于高速设备和全速/低速设备也是不一样的。全速/低速设备的EOP是一个大约为2个数据位宽度的单端0(SE0)信号。SE0的意思就是,D+和D同时都保持为低电平。由于USB使用的是差分数据线,通常都是一高一低的,而SE0不同,是一种都为低特殊的状态。SE0用来表示一些特殊的意义,例如包结束、复位信号等。前面提到USB集线器对USB设备进行复位的操作,就是通过将总线设置为SE0状态大约10ms来实现的。对于高速设备的EOP,使用故意的位填充错误来表示。那么如何判断一个位填充错误是真的位填充错误还是包结束呢?这个由CRC校验来判断。如果CRC校验正确,则说明这个位填充错误是EOP;否则,说明传输出错。具体的定义请参看USB协议,这里只要知道有EOP这么一个东西就行了。
包标识符PID是用来标识一个包的类型的它总共有8位,其中USB协议使用的只有4位(PID~PID3),另外4位(PI4~PID7)是PID~PD3的取反,用来校验PID。USB协议规定了4类包,分别是令牌包(token packet,PD1~0为01)、数据包( data packet,pid1~0为11)、握手包(handshake packet,piD~0为10)和特殊包( special packet,PiD1~0为00)。不同类的包又分成几种具体的包。图2 是USB2.0协议中规定的各种PID,其中有些是在USB1.1协议中没有的,用号标出。
图2 USB2.0中定义的各种PID
以上是数据包的结构以及它们传输的过程,今天的分享就到这里。

在C语言关键字中const举足轻重,我们今天就深度聊一聊const的定义和实际应用,让它不再是迷。
C语言中const关键字是constant的缩写,是恒定不变的意思。通常翻译为常量、常数等,我们一看到const关键字马上就想到了常量。这是不精确的,精确来说应该是只读变量,其值在编译时不能被使用,因为编译器在编译时不知道其存储的内容。那么const推出的初始目的正是为了取代预编译指令,消除它的缺点,同时继承它的优点。
事实上在C语言中const功能很强大,它可以修饰变量、数组、指针、函数参数等。
1、const 修饰的只读变量:
C语言中采用const修饰变量,功能是对变量声明为只读特性,并保护变量值以防被修改。
例如:
const int Max = 100;
int Array[Max];
这个大家可以在Visual C++6.0创建一个.c文件测试一下,你会发现在.c文件中编译器会提示出错。我们知道定义一个数组必须指定其元素的个数,这也从侧面证实在C语言中const修饰的Max仍然是变量,只不过是只读属性罢了。
还有值得注意的是,定义变量的同时,必须初始化,并且不能再重新赋值。
2、节省空间,避免不必要的内存分配,同时提高效率
编译器通常不为普通const只读变量分配存储空间,而是将他们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。
例如:
#define M 3 //宏常量
const int N= 5; //此时并未将N放入内存中
int i = N; //此时为N分配内存,以后不再分配
int I = M; //预编译期间进行宏替换,分配内存
int j = N; //没有内存分配
int J = M; //再进行宏替换,又一次分配内存
const定义的只读变量从汇编的角度来看,只是给出了对应的内存地址,而不是像#define一样给出的是立即数。所以,const定义的只读变量在程序运行过程中只有一份备份(因为它是全局的只读变量,存放在静态区),而#define定义的宏常量在内存中有若干个备份。#define宏是在预编译阶段进行替换,而const修饰的只读变量是在编译的时候确定其值。#define宏没有类型,而const修饰的只读变量具有特定的类型。
3、修饰一般变量
一般变量是指简单类型的只读变量。这种只读变量在定义时,修饰符const可以用在类型说明符前,也可以用在类型说明符后,例如:
int const i = 2; 或 const int i = 2;
4、 修饰数组
C语言中const还可以修饰数组,举例如下:
const int array[5] = {1,2,3,4,5};
array[0] = array[0]+1; //错误
数组元素与变量类似,具有只读属性,不能被更改;一旦更改,如程序将会报错。
5、 修饰指针
C语言中const修饰指针要特别注意,共有两种形式,一种是用来限定指向空间的值不能修改;另一种是限定指针不可更改。举例说明如下:
Const离谁近修饰谁的原则,
例如:
const int * p1; //定义1,p1可变,p1指向的对象不可变
int * const p2; //定义2,p2不可变,p2指向的对象可变
上面定义了两个指针p1和p2。
在定义1中const限定的是*p1,即其指向空间的值不可改变,若改变其指向空间的值如*p1=20,则程序会报错;但p1的值是可以改变的,对p1重新赋值如p1=&k是没有任何问题的。
在定义2中const限定的是指针p2,若改变p2的值如p2=&k,程序将会报错;但*p2,即其所指向空间的值可以改变,如*p2=80是没有问题的,程序正常执行。
6、修饰函数参数
const修饰符也可以修饰函数的参数,当不希望这个参数值在函数体内被意外改变时使用。所限定的函数参数可以是普通变量,也可以是指针变量。举例如下:
void fun1(const int i)
{
其它语句
……
i++; //对i的值进行了修改,程序报错
其它语句
}
告诉编译器i在函数体中不能改变,从而防止了使用者的一些无意或者错误的修改。
void fun2(const int *p)
{
其它语句
……
(*p)++; //对p指向空间的值进行了修改,程序报错
其它语句
}
7、修饰函数的返回值
Const修饰符也可以修饰函数的返回值,返回值不可被改变。
Const int Fun(void);
到这里const的定义和常用的说明我给大家做了描述,有疑问和其他想法欢迎交流~
大家好,我是张飞实战电子黄忠老师,今日分享GPIO结合寄存器以及硬件电路,再来举例子分析输入输出。
通过寄存器的位标注rw,我们可知这个寄存器的某个位是可读(r)并且可写的(w),我们也可以通过读寄存器里面的值得到引脚的配置信息,如果寄存器的位标注只有r或者w,那么就代表这个寄存器的这个位只能进行读(r)或者写(w)。
复位后IO口寄存器的值每一位可能不都是一样的,也就是说复位后IO口的状态、工作模式等不完全相同,一定要注意。
模式配置寄存器GPIOx_MODER,右上角用蓝色圆圈标识的地方告诉我们IO口的复位值,可以看到复位后对于A组IO口来说初始值0XA8000000,对于B组IO口初始值为0x00000280,其他组IO口都是0。该寄存器共 32 位,每 2个位控制 1个IO。
如图中左下角划蓝线的为第0位和第1位。通过往第0位写0,第1位写0配置成Input Mode(输入模式),通过往第0位写0,第1位写1配置成General purpose output Mode(普通输出模式),通过往第0位写1,第1位写0配置成Alternate function Mode(复用功能模式),通过往第0位写1,第1位写1配置成Analog Mode(模拟模式)。
例如我们要把这个寄存器第0位写1,其他都写0,表示如下:
GPIOA->MODER |= 0x00000001;
这就相当于把A组的PA0口配置成了普通输出模式,其他IO口配置成了输入模式。
GPIOx_OTYPER寄存器用于控制 IO 的输出类型,仅用于输出模式,在输入模式下不起作用。该寄存器低 16 位(第0位-第15位)有效,每一个位控制一个 IO 口,根据往不同的位写1(开漏输出)/写0(推挽输出)来配置成不同的输出模式。复位后,该寄存器值均为 0,即默认为推挽输出。
例如我们往A组IO口的第0位写1那就将PA0成开漏输出模式:
GPIOA->OTYPER |= 0x00000001;
GPIOx_OSPEEDR寄存器用于控制 IO的输出速度,仅用于输出模式,在输入模式下不起作用。该寄存器每 2 个位控制一个 IO 口,根据往不同的位写1/清0不同的位来配置成不同的模式。复位后对于A口来说初始值为0X0C000000,对于B口初始值0x000000C0,其他口都是0。
例如我们往A组IO口的第0位和第1位写1那就将PA0成高速输出模式:
GPIOA->OSPEEDR |= 0x00000003;
GPIOx_PUPDR寄存器用于控制 IO 的上拉/下拉,该寄存器每 2 个位控制一个 IO 口, 用于设置上下拉,根据往不同的位写1/清0不同的位来配置成不同的模式。复位后对于A口来说初始值为0X64000000,对于B口初始值0x00000100,其他口都0x0C000000。
例如我们往A组IO口的第0位写1那就将PA0下拉模式:
GPIOA->PUPDR |= 0x00000001;
GPIOx_ODR寄存器是IO口的输出数据寄存器,寄存器低 16 位(第0位-第15位)有效,寄存器每 1 个位控制一个 IO 口, 也就是这个里面位的状态代表了单片机输出的状态,根据往不同的位写1/清0不同的位来配置成不同的模式。复位后都是0。
例如我们往A组IO口的第0位写1那PA0就输出高:
GPIOA->0DR |= 0x00000001;
对于一些其他的寄存器大家可以去参考数据手册,按照上面讲述的方法去配置。
硬件设计:
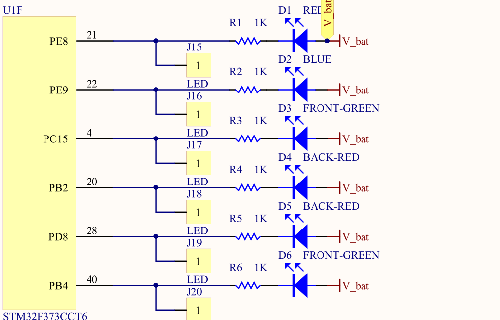
图示LED灯部分我们用到了B组的2PIN(脚的简称)和4PIN, C组的15PIN, D组的8PIN, E组的8PIN和9PIN。
LED灯硬件的设计决定了LED灯的驱动方法,LED灯相当于一个发光二极管,如果单片机引脚输出高,则二极管的左边和右边电压相同,不亮,反之单片机输出低,右边电压大于左边电压通过单片机内部电路形成回路点亮二极管,那麽通过控制引脚输出的高低就控制了LED灯的亮灭。
软件设计:
下面就通过实际的寄存器来配置IO口模块,下面为LED寄存器配置代码:
void Init_GPIO(void)
{
//开启IO时钟
/**********************LED*****************************/
RCC->AHBENR |= (1<<18); //I/O port C clock enabled
RCC->AHBENR |= (1<<19); //I/O port D clock enabled
RCC->AHBENR |= (1<<20); //I/O port B clock enabled
RCC->AHBENR |= (1<<17); //I/O port A clock enabled
RCC->AHBENR |= (1<<21); //I/O port E clock enabled
GPIOB->MODER = 0; //Reset register
GPIOB->OSPEEDR = 0;//Reset register
GPIOB->PUPDR = 0;//Reset register
//GPIOB_Pin2 GPIOB_Pin4
GPIOB->MODER |= 0x00000110; //设置GPIOB_Pin2/Pin4输出模式
GPIOB->OSPEEDR |= 0x00000330;//设置GPIOB_Pin2/Pin4输出速度
GPIOB->ODR |= 0x0014; //设置GPIOB_Pin2/Pin4输出高电平
//GPIOE_Pin8 GPIOE_Pin9
GPIOE->MODER |= 0x00050000; //设置GPIOE_Pin8/Pin9输出模式
GPIOE->OSPEEDR |= 0x000F0000; //设置GPIOE_Pin8/Pin9输出速度
GPIOE->ODR |= 0x0300; //设置GPIOE_Pin8/Pin9输出高电平
//GPIOD_Pin8
GPIOD->MODER |= 0x00010000; //设置GPIOD_Pin8输出模式
GPIOD->OSPEEDR |= 0x00030000; //设置GPIOD_Pin8输出速度
GPIOD->ODR |= 0x0100; //设置GPIOD_Pin8输出高电平
//GPIOC_Pin15
GPIOC->MODER |= 0x40000000; //设置GPIOC_Pin15输出模式
GPIOC->OSPEEDR |= 0xC0000000; //设置GPIOC_Pin15输出速度
GPIOC->ODR |= 0x8000; //设置GPIOC_Pin15输出高电平
}
上面没有配置的寄存器我们使用默认值,通过改变输出数据寄存器(ODR)的值,控制某一个引脚输出高和低控制LED灯的状态。
例如:控制IO输出高电平:
GPIOD->ODR |= 0x0100; //设置GPIOD_Pin8输出高电平
控制IO输出低电平:
GPIOD->ODR &= 0xFEFF; //设置GPIOD_Pin8输出低电平
在这里我们仅配置IO口的推挽高速输出,不上拉,不下拉模式作为演示,大家也可以根据上面介绍的方法去配置调试其他模式,GPIO部分设计实现介绍就在此结束,若有不理解的欢迎交流~
大家好,我是张飞实战电子黄忠老师,今天分享如何通过手册理解单片机IO知识点。
含义解释:
1. GPIO:同我们常说的IO口一样, General Purpose Input Output (通用输入/输出)简称为GPIO,每个GPIO端口可通过软件分别配置成输入或输出模式。
2. 外设:指的是除CPU以外的外围功能模块,只不过这部分电路依旧被封装在单片机内部,比如IO,ADC,DAC,TIM等。
3. 复位:把MCU恢复到最开始的状态,比如说我们把电脑重启了一次,就相当于复位了一次,在这里我们把MCU恢复到初始的状态称为复位。
4. 往某一位写1,在硬件上就相当于把把它设置成高电平,清0则与之相反。
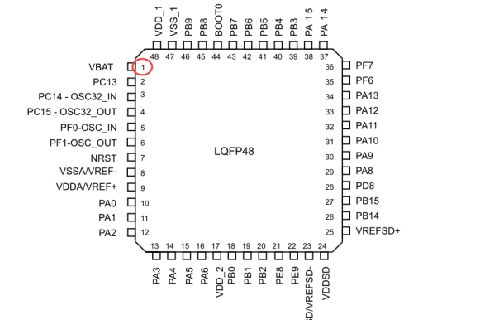
芯片的缩略封装图:
STM32F373CCT6 总共有48个引脚(图中左上角红色圈起来的1代表芯片的1号引脚,后面的以此类推,我们这里把1脚简称1Pin),分以下几个类别:
1.可以编程控制的引脚:PAx(x表示0,1,2…),PBx(x表示0,1,2…)等以相同类似方式命名的。STM32F373CCT6分多组 IO口,分别用大写字母表示,即
x=A/B/C/D/E/F,例如GPIOA,表示A组IO口,这组IO口下面又有很多引脚,那么我们就用PA0,PA1,PA2等方式来表示,每组下面最多16个IO口。通俗点来讲:GPIOA就相当于八年级五班这个班级,PA0,PA1相当于班里的学生,有叫李刚的,有叫张华的等等,每个班最多16个学生。
我们看到有的可编程控制的引脚,例如PC14-OSC32-IN,那么说明这个引脚有多种功能,可以当IO口用,也可以当做OSC32-IN用,在下面我们会具体解释这样的引脚。
2. 不可编程控制的引脚:1Pin(备用电源正脚),7 Pin(复位脚), 8 Pin(模拟电源负脚), 9 Pin(模拟电源/参考电压正脚), 17 Pin(数字电源正脚),23 Pin(SDADC1, SDADC2, SDADC3 地),24 Pin(SDADC1, SDADC2, SDADC3 电源),25 Pin(SDADC1, SDADC2, SDADC3的外部参考电压正),44 Pin(启动内存选择引脚),47 Pin(数字电源负脚),48 Pin(数字电源正脚)。
1. 后备区域供电脚 VBAT 脚的供电采用 CR1220 纽扣电池和 VCC3.3 混合供电的方式,在有外部电源 (VCC3.3) 的时候, CR1220 不给 VBAT 供电, 而在外部电源断开的时候, 则由 CR1220给其供电。这样,VBAT 总是有电的,以保证 RTC 的走时以及后备寄存器的内容不丢失。
2. BOOT0
关于详细的引脚功能定义可以查阅《STM32F373xx》数据手册第33页,这里我们解释下关于引脚的功能问题:
1. 默认功能:也就是引脚的普通功能。
2. 复用功能:即将IO口用作普通输入输出以外的功能,通过配置相关寄存器后选择的功能,例如串口输入输出,使用时需要配置复用模式。
想要配置成复用功能,首先需要查看引脚定义看看这个IO口可不可以被配成复用功能,这个是由IO的内部电路决定的。如果有才可以被配置,配置成复用功能不仅仅是要通过寄存器GPIOx_MODER配制成复用功能模式,而且还要通过GPIOx_AFRL,GPIOx_AFRH寄存器选择IO复用功能。这样IO口才能真正被配成复用功能。
3. 附加功能:配置相关外设寄存器来选择的功能,比方配置ADC使能某些通道等来使能相应管脚的附加功能。同样想要配置成附加功能,首先需要查看引脚定义看看这个IO口可不可以被配成附加功能,这个也是由IO的内部电路决定的。如果有,那么通过寄存器GPIOx_MODER配制成模拟功能模式。
每组通用 I/O 端口包括 4 个 32 位配置寄存器 (MODER、 OTYPER、 OSPEEDR和 PUPDR) 、2 个 32 位数据寄存器(IDR 和 ODR) 、1 个 32 位置位/复位寄存器 (BSRR)、1 个 32 位锁定寄存器 (LCKR) 和 2 个 32 位复用功能选择寄存器(AFRH 和 AFRL)等,可以被配置成一下几种不同的模式:
输入上拉:IO口上拉就是在IO口通过接一个电阻到电源(注意这个电压要和单片机供电电压相同,否则过高会烧毁IO),电阻的大小决定了电源到IO口电流的不同,这就是我们常说的弱上拉等。下面附图一张。
输入下拉:下拉就是在IO口通过接一个电阻到地,电阻的大小决定了IO口到地电流的不同,这就是我们常说的弱下拉等。下面附图一张。
输入浮空/模拟输入:浮空(floating)就是逻辑器件的输入引脚即不接高电平,也不接低电平。浮空最大的特点就是电压的不确定性,它可能是0V,也可能是VCC,还可能是介于两者之间的某个值. 浮空一般用来做ADC输入用,可能有的芯片把浮空模式和模拟输入模式分开了,在此解释一下,在浮空模式下使能了IO的模拟功能就相当于是模拟输入。
开漏输出:开漏输出就是我们所说的OC输出,不输出电压,相当于N型三极管的集电极作为单片机的IO口,需要在外部加一个上拉电阻配合使用。如图:
推挽输出:可以输出高,低电平,但相对于普通的输出而言,这种输出方式增加了输出能力。如图:
复用开漏输出、复用推挽输出:可以理解为GPIO口被用作第二功能时的配置情况(即并非作为通用IO口使用)。
上图为引脚的内部电路框图(红圈内或旁边数字代表序号,下面简称1号等)
输出部分解析:输出分三路
第一路,1号(读/写动作-由片内外设控制)——>3号(经过一个逻辑门->输出控制电路)
第二路,15号(写动作)——>14号(Bit Set/Reset register 位设置/清零寄存器),——>13号(Output data register数据输出寄存器)——>3号(经过一个逻辑门->输出控制电路)
第三路,2号(复用功能输出)——>3号(经过一个逻辑门->输出控制电路)。
三路都通过控制4号(MOS管电路,根据配置的不同模式,驱动P-MOS或者N-MOS或者两个一起驱动)——>5/7号的下拉/上拉电阻(我们可以看到上/下拉电阻有开关控制,意思就是可以通过外部的某些东西去控制使能或者失能上/下拉)——>6号的保护二极管(这里利用了二极管钳位的功能,可以在一部分程度上起到保护引脚的作用)——>IO口。
输入操作解析:同样分三路
第一路,IO口——>6号的保护二极管输出到——>9号(模拟输入)——> 片上外设
第二路,IO口——>6号的保护二极管输出到——>8号(开关,可靠外部控制)——>10号(复用功能输入)——> 片上外设
第三路,IO口——>6号的保护二极管输出到——>8号(开关,可靠外部控制)——>12号(Input data register输入数据寄存器)——> 11号(可供读取数据)。
如何结合寄存器以及硬件电路来实现具体输入输出请看下篇分析~
 黄忠
黄忠