电源
91篇文章

大家好!我是张飞实战电子黄忠老师!今天给大家聊一聊单片机堆栈.
单片机堆栈是什么?
简单来说是在RAM区的一块存储空间,在系统空间中用作临时数据存储,遵循后进先出的原则。
栈空间操作的关键点之一就是栈指针寄存器,每次执行栈操作时,栈指针的内容自动调整。
按照通常的说法,向栈中存储数据称为“压栈”(使用PUSH指令),恢复数据称为“出栈”(使用POP指令)。根据所使用架构的不同,有些处理器在向栈存入数据时地址会自动增加,而有些则会减小。
这就意味着栈指针始终指向栈空间的最后一个数据,在执行数据存储前(PUSH),栈指针会首先减小。
PUSH和POP通常用在函数或子程序的开始和结尾处。在函数开始执行时,PUSH操作将寄存器的当前内容存入栈空间;执行结束前,POP又将栈空间存储的数据恢复。一般说来,对每个寄存器的PUSH操作都应相应的进行POP操作。否则恢复的数据可能无法对应之前的寄存器,这样会导致无法预期的后果,比如栈溢出。
下面看一下压栈和出栈的操作过程:
再来说一下堆栈的作用:
子程序调用和中断服务时,CPU自动将当前PC值压栈保存,返回时自动将PC值弹栈。
保护现场/恢复现场。
数据传输
再来说一下堆栈操作的一些规则。
比如Cortex-M0处理器每次出栈以及压栈操作的最小单位是4字节(32位),还可以使用一条指令实现对多个寄存器的压栈和出栈操作。显然Cortex-M0的栈空间被设计为字对齐的(地址值必须是4的倍数,比如0x0、0x4、0x8等)。
对于Cortex-M0处理器,可以通过R13或SP访问R13或SP,根据处理器状态和CONTROL寄存器值的不同,访问的栈指针可以是主栈指针(MSP),也可以是进程栈指针(PSP)。许多简单的应用只会用到一个栈指针,一般默认是主栈指针(MSP),进程栈指针通过只用于嵌入式应用的操作系统(OS)。
对于Cortex-M0处理器由于栈是向下生长的(满递减),内存的上边界通常会被用作栈指针的初始值。例如,如果内存区域为0x20000000~0x20007FFF,我们可以将栈指针的初始值设为0x20008000,在这种情况下,第一次压栈操作会将数据存至0x20007FFC开始的字中,这也是内存的最高4字节。
大家好,我是张飞实战电子的黄忠老师,今天我们来讲解单片机电源管理。
市场上的产品越来越多的低功耗需求,对于单片机的电源管理就要求越来越高,关注度自然也会增加。
一起看一下Cortex-M3对于电源管理的一些特性吧。
1、休眠模式
Cortex-M3提供的休眠模式为一种电源管理特性,在休眠模式中,系统时钟可能会停止,而自由运行时钟输入仍可能在运行,以便处理器可由中断唤醒。
处理器有下面两种休眠模式:
休眠:Cortex-M3处理器的SLEEPING信号表示休眠状态
深度休眠:Cortex-M3处理器的SLEEPDEEP信号表示深度休眠状态
NVIC系统控制寄存器的SLEEPDEEP位决定休眠模式的类型。
休眠模式由等待中断(WFI)或等待事件(WFE)指令触发,事件可以是中断、之前触发的中断或者通过接收事件(EXEV)信号生成的信号脉冲。处理器内部具有事件锁存,因为之前的时间也可以将处理器从WFE中唤醒。
根据芯片的不同设计,进入休眠模式后处理器的实际动作可能会不同,不过一般是停止一些时钟以降低功耗,或者可能的话将芯片整个关掉,所有的时钟信号也会因此停止。在芯片被完全关掉的情况下,只能通过系统复位唤醒系统。
1、退出休眠特性
休眠模式的另外一个特性为它可以被设置为在退出中断程序后自动回到休眠。这样若没有需要处理的中断,内核就可以一直保持休眠状态。要使用这个特性,我们需要设置系统控制寄存器里的SLEEPONEXIT位。
应该注意的是,若使能了退出休眠特性,处理器可以在任何异常退出时进入休眠,即便是没有执行WFE/WFI指令。要确保处理器只在需要时进入休眠,那么若系统未准备好进入休眠,就不要设置SLEEPONEXIT位。
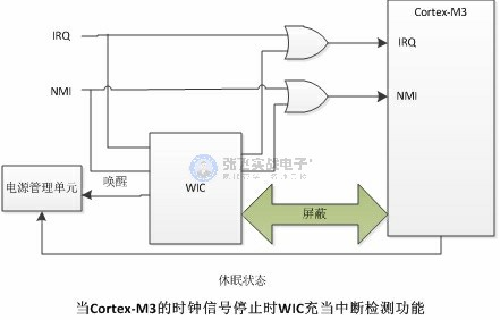
2、唤醒中断控制器
唤醒中断控制器(WIC)在Cortex-M3中作为一种可选单元出现,它被连接到已有的NVIC上,并且在中断到达时产生唤醒请求。
从软件的角度来看,WFI和WFE的效果是一样的。WIC中没有可编程寄存器,它可以从NVIC的接口上得到所需的所有信息。通过WIC的使用,进入处理器内核的时钟信号可以完全停止。当有中断请求到达时,WIC会向芯片中的系统控制器或电源管理单元(PMU)发出唤醒请求,通知芯片恢复处理器时钟。
USB协议规定了4中传输类型:批量传输,等时传输,中断传输和控制传输.我们已经有相关文章介绍了批量传输,接着下面我们来说说中断传输和等时传输.
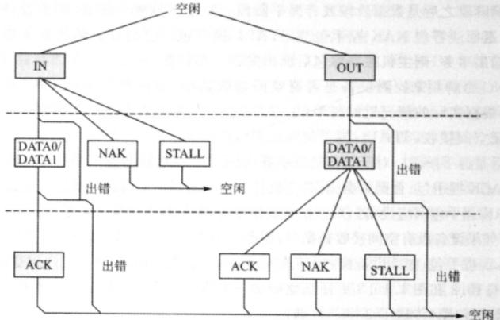
中断传输是一种保证查询频率的传输中断端点在端点描述符中要报告它的查询间隔,主机会保证在小于这个时间间隔的范围内安排一次传输这里所说的中断,跟我们硬件上的中断是不一样的。它不是由设备主动地发出一个中断请求,而是由主机保证在不大于某个时间间隔内安排一次传输。中断传输通常用在数据量不大,但是对时间要求较严格的设备中,例如人机接口设备(HID)中的鼠标、键盘、轨迹球等。中断传输也可以用来不断地检测某个状态,当条件满足后再使用批量传输来传送大量的数据。除了在对端点查询的策略上不一样之外中断传输和批量传输的结构基本上是一样的,只是中断传输中没有PING和NYE两种包。中断传输使用中断事务(interrupt-transaction),中断事务的流程图如图1所示
等时传输(同步传输)用在数据量大、对实时性要求高的场合,例如音频设备、视频设备等,这些设备对数据延迟很敏感。对于音频或者视频设备来说,对数据的100%正确要求不高,少量数据的错误还是能够容忍的,主要的是要保证不能停顿;所以等时传输是不保证数据100%正确的。当数据错误时,并不进行重传操作。因此等时传输也就没有应答包。数据是否正确,可以由数据包的CRC校验来确认。至于出错的数据如何处理,由软件来决定。等时传输使用等时事务(isochronous-transaction)来传输数据。图2是等时事务的流程图
以上就是中断传输和等时传输了,你明白了吗?

指针和数组有没有关系呢?到底有什么关系,今天我们就来好好的看一看。
指针就是指针,指针变量在32位系统下,永远占4字节,其值为某一个内存的地址。指针可以指向任何地方,但是不是任何地方你都能通过这个指针变量访问到呢?
数组就是数组,其大小与元素的类型和个数有关;定义数组时必须指定其元素的类型和个数;数组可以存任何类型的数据,但不能存函数。
既然它们之间没有任何关系,那为何很多人经常把数组和指针混淆,甚至很多人认为指针和数组是一样的呢?我们先来看下吧。
1、以指针的形式访问和以下标的形式访问
下面我们就详细讨论讨论它们之间似是而非的一些特点。例如,函数内部有如下定义:
(A)char *p = “abcdef”;
(B)char a[ ] = “abcdef”;
①以指针的形式访问指针和以下标的形式访问指针
以指针的形式:*(p+4)
以下标的形式:p[4]
这里的4 是偏移量,都是先取出p里存储的地址值,加上偏移量,计算出新的地址,然后从新的地址中取出值。那么上面形式不同,访问的本质是一样的。
②以指针的形式访问数组和以下标的形式访问数组
以指针形式:*(a+4)
以下标形式:a[4]
我们都知道数组名代表数组首元素的首地址,加上4个元素的偏移量,得到新的地址,然后取出新地址上的值。
由此得出指针和数组都是可以“以指针的形式”或“以下标的形式”进行访问,但是是完全不一样的东西。
还有需要注意的是这个偏移量代表的是元素,而不是字节,偏移元素的个数再计算新的地址取值。
2、a 和 &a 的区别
先来举个例子:
int a[5] = {1,2,3,4,5},b,c;
int *prt = (int *)(&a + 1);
b = *(a+1);
c = *(ptr-1);
对指针进行加1操作,得到的是下一个元素的地址,而不是原有地址值直接加1,所以一个类型为T的指针的移动,以sizeof(T)为移动单位。因此,对上面例子来说,a是一个一维数组,数组中有5个元素,所以&a+1是取数组a的首地址,该地址的值加上sizeof(a)的值,也就是&a+5*sizeof(int),也就是下一个数组的首地址,显然当前指针已经越过了数组的界限。
那么*(a+1):a和&a的值是一样的,但是意思不一样,a是数组首元素的地址,也就是a[0]的首地址,&a是数组的首地址,a+1是数组下一个元素的首地址,也就是a[1]的首地址,&a+1是下一个数组的首地址,所以b的值应该是输出2,*(ptr-1),因为前面我们分析ptr是指向a[5]的,并且ptr是int*类型,所以*(ptr-1)是指向a[4],输出为5。
由此我们可以得知数组名a代表的是数组首元素的首地址,而不是数组的首地址,&a才是整个数组的首地址。
指针和数组你能完全理清楚了吗?

在我们前面的文章里面,我们描述了什么是批量传输,中断传输,等时传输,下面的文章我们来介绍一下控制传输。
控制传输与前面三种传输相比,要稍微复杂一些。前面在介绍设备的枚举过程时,就提到过控制传输。控制传输分为三个过程:第一个过程是建立过程;第二个过程是可选的数据过程;第三个过程是状态过程。
建立过程使用一个建立事务。建立事务是一个输出数据的过程,与批量传输的输出事务相比,有几处不一样:首先是令牌包不一样,建立过程使用 SETUP令牌包;其次是数据包类型, SETUP只能使用DATA0包;最后是握手包,设备只能使用ACK来应答(除非出错了,不应答),而不能使用NAK或者 STALL来应答,即设备必须要接收建立事务的数据。图1是建立事务的流程图.
图1
数据过程是可选的,即一个控制传输可能没有数据过程。如果有,一个数据过程可以包含一笔或者多笔数据事务。控制传输所使用的数据事务与批量传输中的批量事务是一样的。要注意的是,在数据过程中,所有的数据事务必须是同一个传输方向的。也就是说,在控制读传输中,数据过程中的所有数据事务都必须是输入的;在控制写传输中,数据过程中的所有数据事务都必须是输出的。一旦数据传输方向发生改变,就会认为进入到了状态过程。数据过程的第一个数据包必须是DATA1包,然后每次正确传输一个数据包后就在DATA0和DATA1之间交替。
状态过程也是一笔批量事务,它的传输方向刚好跟前面的数据阶段相反,即控制写传输在状态过程使用一个批量输入事务;控制读传输在状态过程使用一个批量输出事务。状态过程只使用DATA1包。
控制传输之所以要弄得这么复杂,是因为它要保证数据传输过程的数据完整性。设备枚举过程中各种描述符的获取以及设置地址、设置配置等,都是通过控制传输来实现的。关于USB协议中定义的控制传输所使用的各种标准请求的数据结构和请求命令,将会在后面的实例中具体、详细地分析。
接下来我们来说一下端点类型和传输类型的关系。一个具体的端点,只能工作在一种传输模式下。通常,我们把工作在什么模式下的端点,就叫做什么端点。例如,控制端点、批量端点等。端点0是每个USB设备都必须具备的默认控制端点,它一上电就存在并且可用。设备的各种描述符以及主机发送的一些命令,都是通过端点0传输的。其他端点是可选的,需要根据具体的设备来决定。非0端点只有在 Set Config之后才能使用。
今天就跟大家分享到这里,你学会了吗?
 黄忠
黄忠